阿里团队发布肖像视频生成框架EMO
阿里巴巴团队发布音频驱动的人像视频生成框架EMO(EmotePortraitAlive),相关论文同步发表在arXiv。
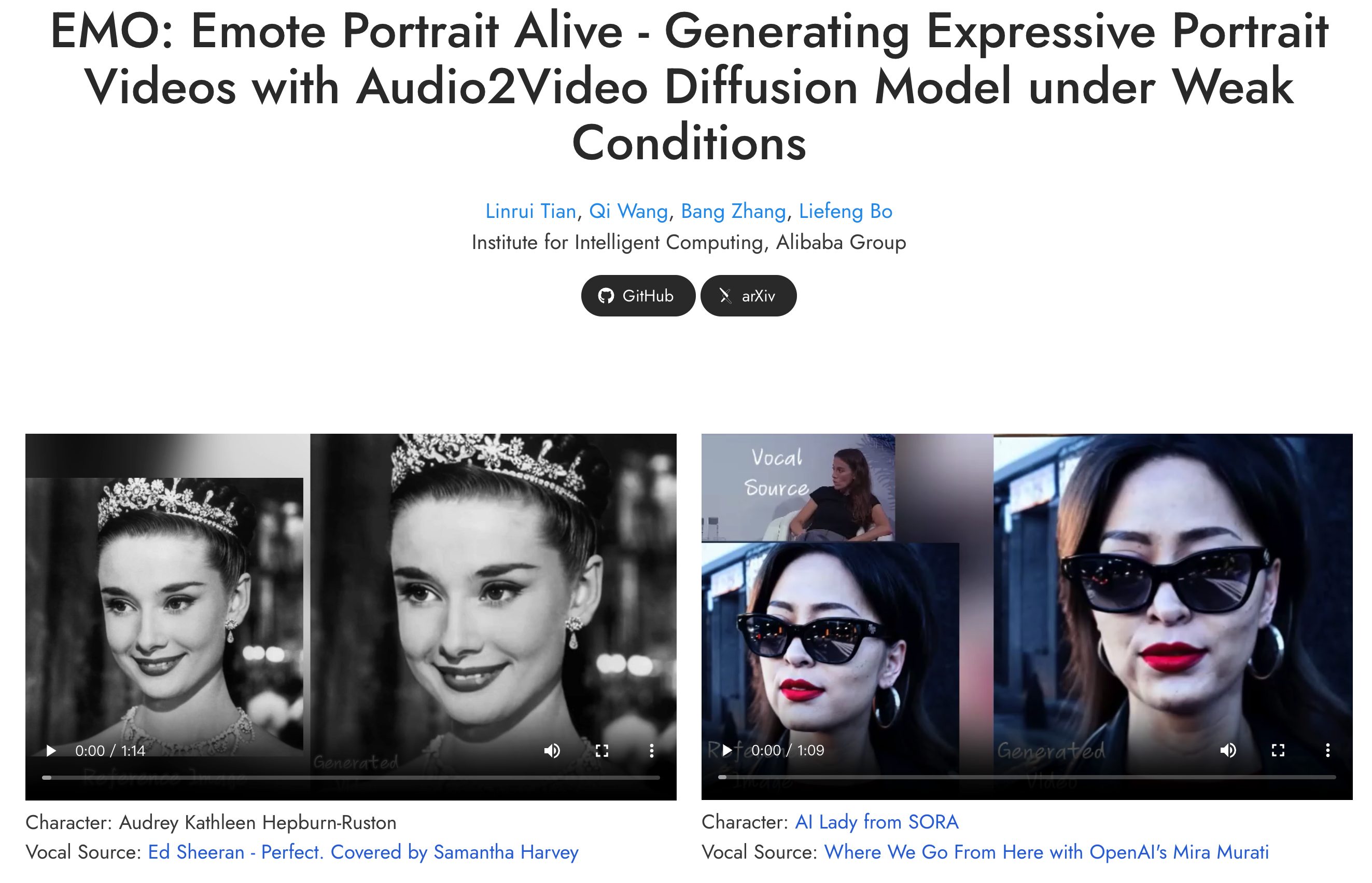
输入参考图像和语音音频,该框架能够生成具有丰富面部表情和头部姿势的语音肖像视频。 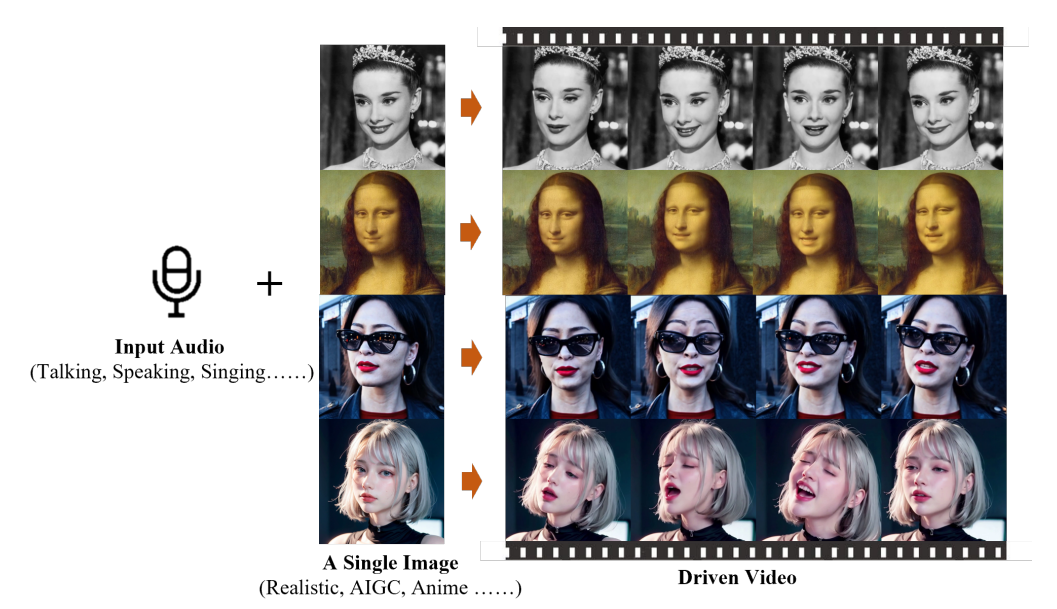 EMO的工作过程分为两个主要阶段:首先,使用参考网络(ReferenceNet)从参考图像和动作帧中提取特征;然后,使用预训练的音频编码器处理声音并嵌入,然后结合多帧噪声和人脸Regionmask生成视频。该框架还集成了两种注意力机制和一个时间模块以确保一致性判断视频中的人物身份和动作自然流畅。这个过程相当于AI先看照片,然后打开声音,跟随声音一一画出视频中每一帧的变化图像。
EMO的工作过程分为两个主要阶段:首先,使用参考网络(ReferenceNet)从参考图像和动作帧中提取特征;然后,使用预训练的音频编码器处理声音并嵌入,然后结合多帧噪声和人脸Regionmask生成视频。该框架还集成了两种注意力机制和一个时间模块以确保一致性判断视频中的人物身份和动作自然流畅。这个过程相当于AI先看照片,然后打开声音,跟随声音一一画出视频中每一帧的变化图像。
EMO的技术报告指出:实验结果表明,EMO不仅可以生成令人信服的说话视频,还可以生成各种风格的歌唱视频,无论是在表现力上还是明显优于现有的DreamTalk、Wav2Lip和SadTalker等先进方法和真实感。目前,研究团队认为该模型的潜在应用方向将集中在:提高数字媒体和虚拟内容生成的技术水平,尤其是在对真实感和表现力要求较高的场景中。
然而,在别人眼中,EMO模式很可能成为别有用心的人手中的犯罪工具。
犯罪份子最喜欢这种开源工具了,又推动了黑产的发展。
飞鱼视频下载助手
本站不缓存任何网站的视频内容,涉及的视频和图片归相关网站及作者所有,如有侵权,敬请来信联系我们,我们立即作出相应的调整。
Copyright © 2023 ~ 2026 飞鱼视频下载助手 All rights reserved.
关于我们
关于网站
版权说明
会员说明
服务条款
隐私政策
更多教程
视频下载完整使用教程
如何获取网站的Cookie
苹果safari浏览器视频保存
联系我们